
裁剪:裁剪部 HYZj波多野结衣图片
【新智元导读】NeurIPS 2024最好论文终于崇拜揭晓了!本年,来自北大字节,以及新加坡国立大学等机构的团队摘得桂冠。
刚刚,NeurIPS 2024最好论文放榜了!

果不其然,本年两篇最好论文鉴别颁给了北大字节团队,和新加坡国立大学Sea AI Lab团队。

除此除外,大会还公布了「数据集与基准」赛说念的最好论文,以及主赛说念最好论文奖委员会,数据集和基准赛说念最好论文奖委员会。

本年,是NeurIPS第38届年会,于12月9日-15日在加拿大温哥华崇拜拉开帷幕。

前段时辰,NeurIPS 2024刚刚公布的时辰提醒奖,鉴别颁给了Ilya Sutskever的Seq2Seq,和Ian Goodfellow的GAN。
有网友发现,Ilya还是连结三年拿下该奖,不错创历史了。
2022年AlexNet,2023年Word2Vec,2024年Seq2Seq
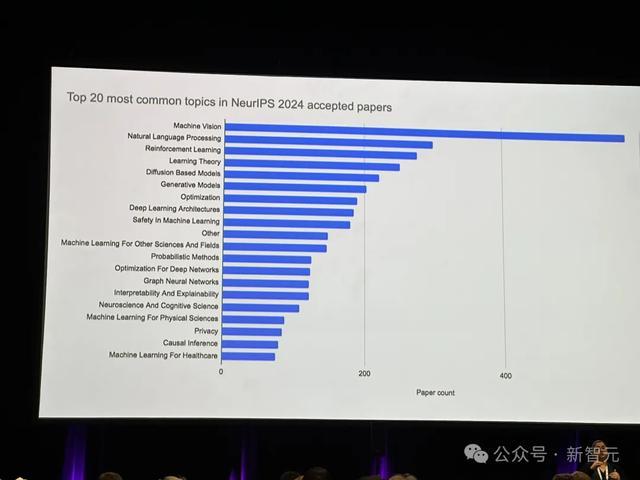
本年,NeurIPS 2024的总投稿数目再创新高,共有15000多篇论文提交,寄托率为25.8%。
从议论内容主题的合座散布来看,主要蚁合在大模子、文生图/文生视频、强化学习、优化这四大块。
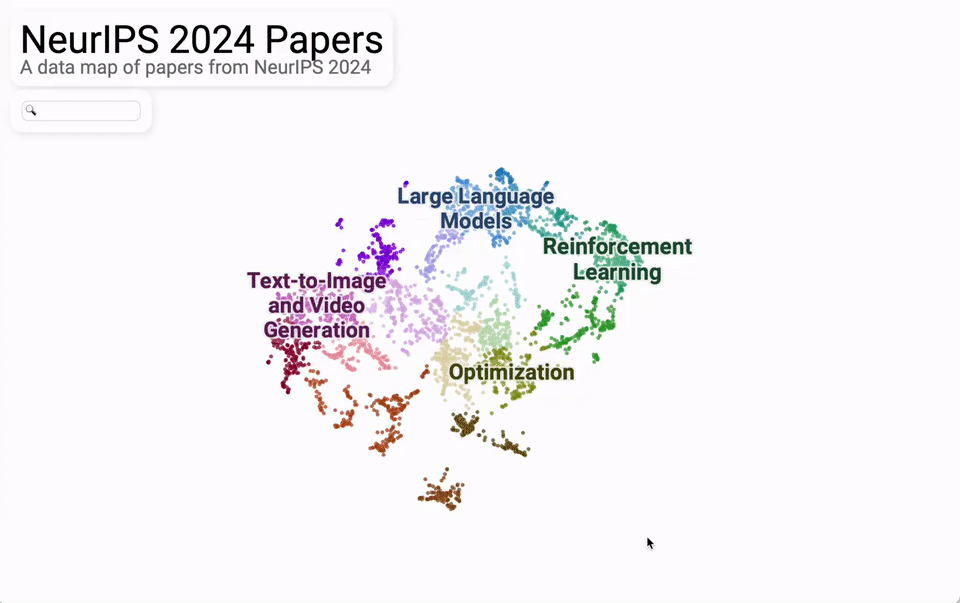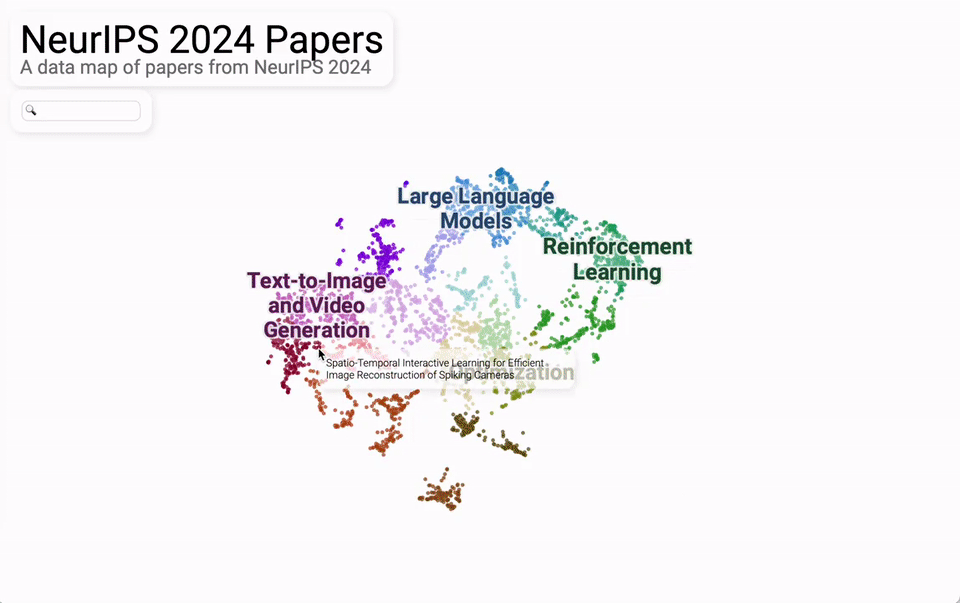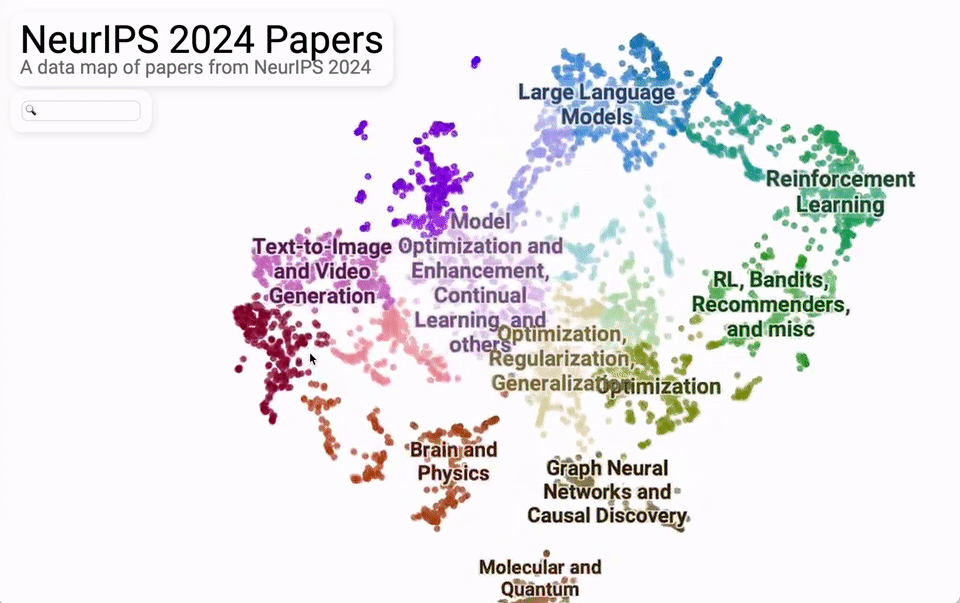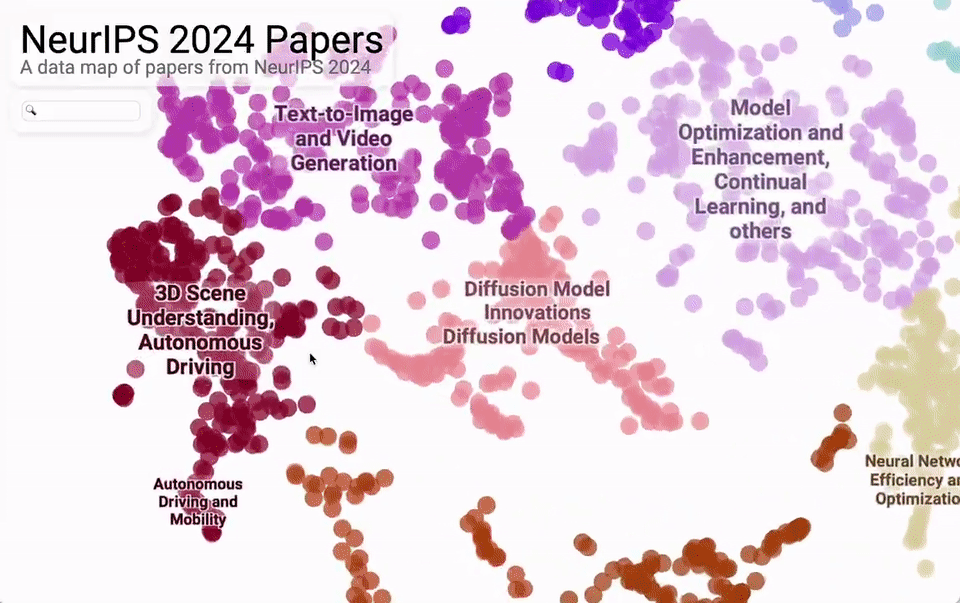
再细分来看,机器视觉、天然话语处理、强化学习、学习表面、基于扩散的模子是最热的5个话题。
系数165000名参会者,也创下积年新高。

获奖论文一:卓著扩散,VAR开启视觉自总结模子新范式
拿下最好论文的第一篇,是由北大字节团队共同提议的一种全新范式——视觉自总结建模(Visual Autoregressive Modeling,VAR)。
(论文详解请点此处)

论文地址:https://arxiv.org/abs/2404.02905
与传统的光栅扫描「下一个token揣度」设施有所不同,VAR再行界说了图像上的自总结学习,选拔粗到细的「下一个法度揣度」或「下一个分辨率揣度」。
这种浅薄直不雅的设施使得自总结(AR)Transformer约略快速学习视觉散布,何况具有较好的泛化智力:VAR首次使得近似GPT的AR模子在图像生成中卓著了扩散Transformer。

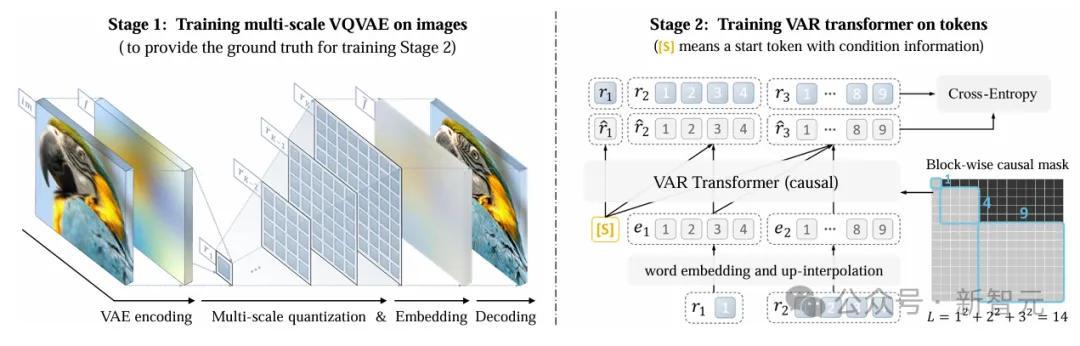
率先,将图像编码为多法度的token映射,然后,自总结过程从1×1token映射起首,并缓缓推广分辨率。
在每一步中,Transformer会基于之前通盘的token映射去揣度下一个更高分辨率的token映射。
VAR包括两个孤立的提醒阶段:在图像上提醒多法度VQVAE,在token上提醒VAR Transformer。
第一阶段,多法度VQ自动编码器将图像编码为K个token映射R=(r1,r2,…,rK),并通过复合死亡函数进行提醒。
第二阶段,通过下一法度揣度对VAR Transformer进行提醒:它以低分辨率token映射 ([s],r1,r2,…,rK−1)作为输入,揣度更高分辨率的token映射 (r1,r2,r3,…,rK)。提醒过程中,使用防护力掩码确保每个rk仅能见谅 r≤k。提醒想法选拔法度的交叉熵死亡函数,用于优化揣度精度。
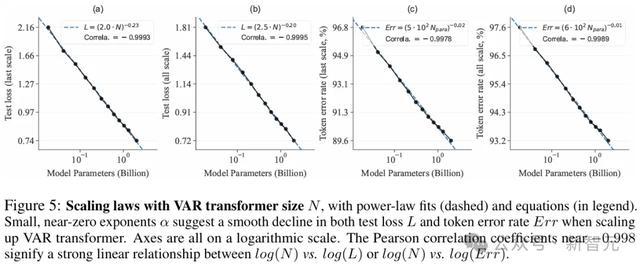
实考解释,VAR在多个维度上卓著了扩散Transformer(DiT),包括图像质地、推理速率、数据服从和可推广性。
其中,VAR初步师法了谎话语模子的两个要紧特质:Scaling Law和零样本泛化智力。

获奖论文二:STDE,破解高维高阶微分算子的筹办贫苦
第二篇获奖论文,是由新加坡国立大学和Sea AI Lab提议的一种可通过高阶自动微分(AD)高效评估的摊派决策,称为当场泰勒导数臆想器(STDE)。

论文地址:https://openreview.net/pdf?id=J2wI2rCG2u
这项责任接头了优化神经采集在处理高维 (d) 和高阶 (k) 微分算子时的筹办复杂度问题。
当使用自动微分筹办高阶导数时,导数张量的大小跟着O(dk)推广,筹办图的复杂度跟着 O(2k-1L)增长。其中,d是输入的维度(域的维度),k是导数的阶数,L是前向筹办图中的操作数目。
在之前的议论中,对于多维推广dk,使用的是当场化技艺,将高维的多项式增长变为线性增长;对于高阶推广 2k-1,则通过高阶自动微分处理了一元函数(即d=1)的指数增长问题。
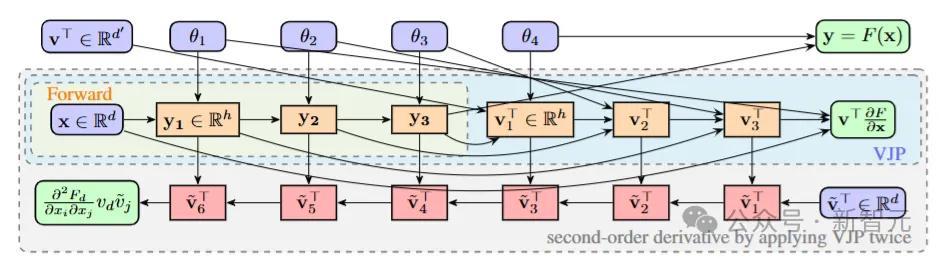
通过反向步地自动微分(AD)的叠加应用,筹办函数F(⋅)的二门道度的筹办图。该函数包含4个基本操作(L=4),用于筹办Hessian矩阵与向量的乘积。红色节点默示在第二次反向传播过程中出现的余切节点。跟着向量-雅可比积(VJP)的每次叠加应用,功令筹办的长度会加倍
在议论中,团队展示了若何通过适应构造输入切向量,诈欺一元高阶自动微分,灵验践诺多元函数导数张量的纵情阶减弱,从而高效当场化任何微分算子。
该设施的中枢念念想是「输入切向量构造」。通过构造特定的「输入切向量」(场合导数),不错将多维函数的高阶导数筹办养息为一元高阶自动微分问题。这意味着将复杂的多元导数运算养息为多个一元导数运算,从而减小了筹办复杂度。
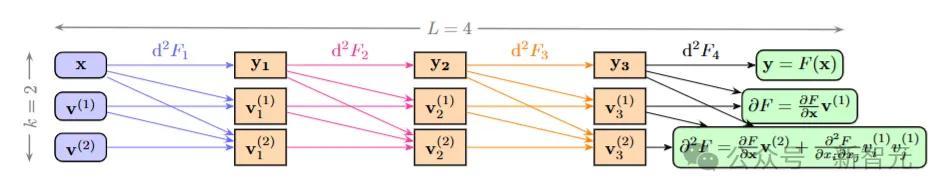
该筹办图泄漏了函数F的二阶导数d²F,其中F包含4个基本操作,参数θi被不祥。最左侧的第一列默示输入的二阶射流(2-jet)
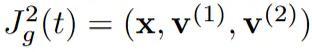
,并通过d²F1将其推向下一列中的二阶射流
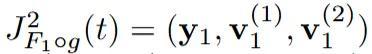
。每一溜齐不错并行筹办,且不需要缓存评估轨迹
将该设施应用于物理信息神经采集(PINNs)时,相较于使用一阶自动微分的当场化设施,该决策在筹办速率上提高了1000倍以上,内存占用减少了30倍以上。
借助该设施,议论团队约略在一块NVIDIA A100 GPU上,在8分钟内求解具有百万维度的偏微分方程(PDEs)。
这项责任为在大范围问题中使用高阶微分算子征战了新的可能性,稀奇是在科学筹办和物理模拟中具有要紧兴致。

「数据集与基准」最好论文
这篇由牛津、宾大等12家机构联手提议的数据集PRISM,荣获了「数据集与基准」赛说念的最好论文。

论文地址:https://openreview.net/pdf?id=DFr5hteojx
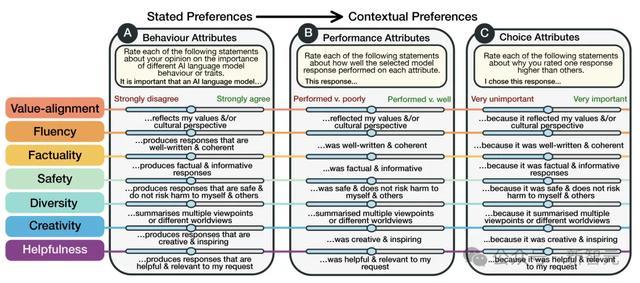
这篇论文通过采集来自75个国度、1500多名参与者的详实反应,科学家们首次全面绘画了AI模子与东说念主类交互的复杂图景。
它就像是为AI「验血」:不单是是检查技艺盘算,更是深化了解AI与不同文化、不同布景东说念主群的交互细节。

具体来说,议论东说念主员采集了东说念主们与21个大模子交互的8,011次信得过数据。
而且,他们还详实记载了参与者的社会东说念主口学特征和个东说念主偏好。
最舛误的是,这项议论聚焦了主不雅和多文化视角中,最具挑战性领域,尤其是见谅价值不雅联系和有争议问题上的主不雅和多元文化视角。
通过PRISM数据集,为将来议论提供了新的视角:
- 扩地面理和东说念主口统计学的参与度
- 为英国、好意思国提供具有东说念主口普查代表性的样本
- 缔造了个性化评级系统,可追想参与者详实布景
总的来说,这项议论具有要紧的社会价值,并推进了对于RLHF中多元化和不合的议论。
NeurIPS 2024实验:LLM作为科学论文作家清单助手的后果评估
跟着大奖出炉后,NeurIPS 2024终于公布了将大模子作为清单助手的后果评估线路。
如今,天然存在着不准确性和偏见等风险,但LLM还是起首被用于科学论文的审查责任。
而这也激励了一个弥留的问题:「咱们如安在会议同业评审的应用中负连累且灵验地诈欺LLM?」
本年的NeurIPS会议,迈出了回答这一问题的第一步。

论文地址:https://arxiv.org/abs/2411.03417
具体来说,大会评估了一个相对明确且低风险的使用场景:字据提交法度对论文进行核查,且收尾仅泄漏给论文作家。
其中,投稿东说念主会收到一种可取舍使用的基于LLM的「清单助手」,协助检查论文是否适应NeurIPS清单的条款。
随后,议论东说念主员会系统地评估这一LLM清单助手的益处与风险,并聚焦于两个中枢问题:
1. 作家是否定为LLM作家清单助手是对论文提交过程的一种有价值的增强?
2. 使用作家清单助手是否能显赫匡助作家改进其论文提交?
最终论断如下:
「LLM清单助手不错灵验地匡助作家确保科学议论的严谨性,但可能不应作为一种敷裕自动化的审查用具来取代东说念主工审查。」

1. 清单助手有用吗?
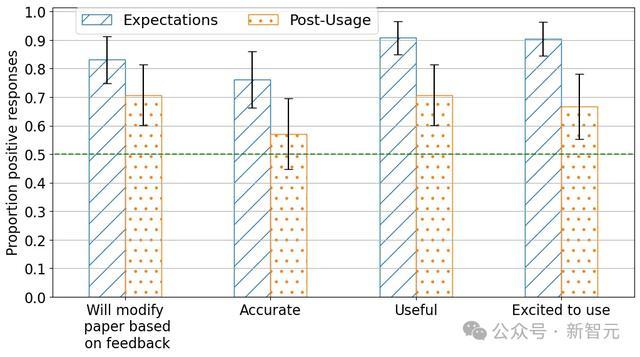
议论东说念主员对作家们进行了问卷拜访,以便了解他们对使用清单助手前后的守望和感受。
拜访共收到539份使用前问卷回话,清单助手共处理了234份提交,同期收到了78份使用后问卷回话。
收尾泄漏,作家浩荡觉得清单助手是对论文提交过程的一项有价值的改进——
大多数给与拜访的作家默示,使用LLM清单助手的体验是积极的。其中,高出70%的作家觉得用具有用,高出70%的作家默示会字据反应修改论文。
值得防护的是,作家在实践使用之前对助手灵验性的守望比实践使用后的评价更为积极。相比使用前后的反应不错发现,在「有用性」和「期待使用」方面的正面评价出现了具有统计学兴致的显赫下落。
2. 清单助手的主要问题是什么?
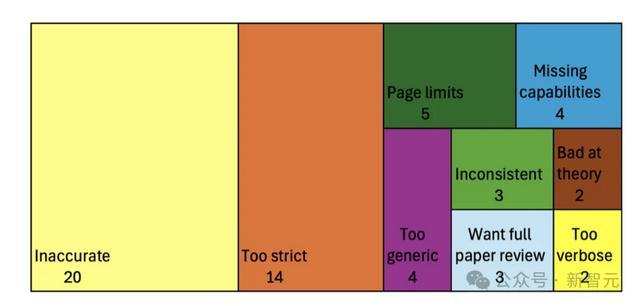
小电影网站作家使用清单助手时遭受的问题,按类别归纳如下。
主要问题包括:不准确性(52名回话者中有20东说念主提到),以及LLM对条款过于尖刻(52名回话者中有14东说念主提到)。
3. 清单助手提供了哪些类型的反应?
议论者使用了另一个LLM,从清单助手对每个清单问题的回话中索取舛误点,将其归类。
以下展示了作家清单助手在清单的四个问题上提供的常见反应类别:
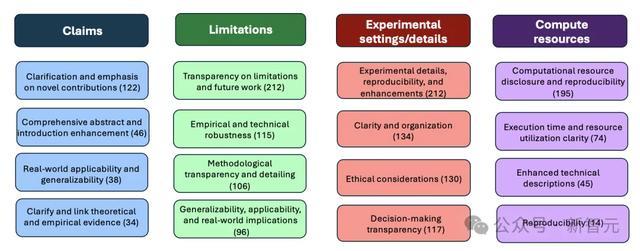
LLM 约略纠合论文内容和清单条款,为作家提供具体的反应。对于清单中的15个问题,LLM频繁会针对每个问题提供4-6个不同且具体的反应点。
尽管其回话中偶然包含一些模板化内容,并可能推广问题的范围,但它也约略针对许多问题提供具体且明确的反应。
4. 作家是否确凿修改了提交的内容?
字据反应,许多作家默示规划对他们的提交内容作念出本质性的修改。
在78名回话者中,有35东说念主具体确认了他们会字据清单助手的反应对提交内容进行的修改。其中包括,改进清单谜底实在认,以及在论文中添加更多对于实验、数据集或筹办资源的细节。
在40个实例中,作家将他们的论文提交到清单考证用具两次(总共提交了80篇论文)。
收尾泄漏,在这40对(两次提交的)论文中,有22个实例中作家在第一次和第二次提交之间至少革新了清单中的一个谜底(举例,从「NA」改为「是」),何况在39个实例中革新了至少一个清单谜底实在认。
在革新了清单确认的作家中,许多作家进行了浩荡修改,其中35/39在清单的15个问题中革新了高出6个确认。
天然并弗成将这些修改因果归因于清单助手,但这些修改标明作家可能在提交之间选拔了助手的反应。
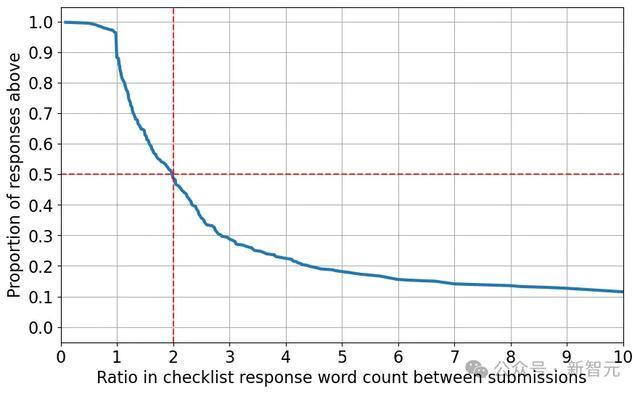
以下是在作家革新确认的问题中,从初度提交到最终提交的字数增长情况(值为2默示谜底长度增多了一倍)。
不错看到,手脚家革新清单谜底时,高出一半的情况下,他们将谜底确认的长度增多了一倍以上。
总结来说,手脚家屡次向清单助手提交时,他们险些齐会在提交之间对清单进行修改,并显赫延伸了谜底的长度,这标明他们可能字据LLM的反应添加了内容。
5. 清单助手是否不错被操控?
清单助手的联想初志,是匡助作家改进论文,而不是作为审稿东说念主考证作家回答准确性的用具。
要是该系统被用作审稿经由中的自动考证关节,这可能会激励作家「操控」系统,从而激励以下问题:作家是否不错借助AI,在无需对论文作念出实践修改的情况下,自动普及清单回答的评价?
要是这种操控是可能的,作家可能会在莫得(太多)额外勉力且空幻际改进论文的情况下,向会议提供极端的合规印象。
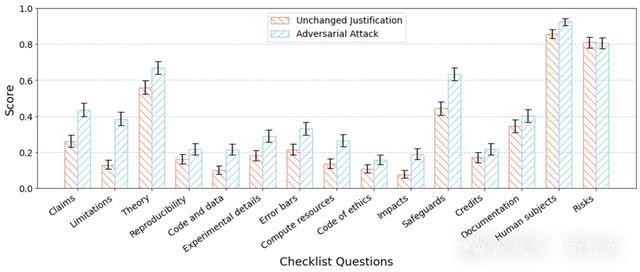
为了评估系统是否容易受到这种操控,议论者使用另一个LLM作为挫折智能体,迭代性地修改清单确认,试图误导清单助手。
在这一迭代过程中,挫折智能体在每轮之后从系统招揽反应,并诈欺反应优化其确认。
议论者向GPT-4提供了开动的清单回答,并交流其仅字据反应翻新确认,而不编削论文的基础内容。允许挫折智能体进行三次迭代(与部署助手的提交按捺一致),智能体在每次迭代中取舍得分最高的清单问题回答。
为了以统计表情量化这种挫折的奏凯率,议论者将采选实在认提交给清单助手进行评估,得回「评分」(当清单助腕默示清单问题「无问题」时得分为1,当助手识别出问题时得分为0)。
以下展示了该挫折的收尾:
论断
通过在NeurIPS 2024部署了一个基于LLM的论文清单助手,解释了LLM在普及科学投稿质地方面的后劲,稀奇是通过匡助作家考证其论文是否适应提交法度。
然而,议论指出了在科学同业评审过程中部署LLM时需要惩处的一些显赫局限性,尤其是准确性和契合度问题。
此外,系统在派遣作家的操控时空匮对抗力,这标明尽管清单助手不错作为作家的扶持用具,但可能无法灵验取代东说念主工评审。
NeurIPS将在2025年链接改进基于LLM的计谋评审波多野结衣图片。